
这几天有点蛋疼,合并功能的时候发现C#实在是太过高端导致导出的DLL都是没法被他直接拿来用的,用C++的CLR+ C# DLL始终挂载不上去,考虑到主要模块是拿来实现与路由器的模拟登陆的,所以干脆自己写了一个HTTP协议来实现这个功能,实现简单的GET和POST请求就可以了。
当然在这里面也是因为没学过C++,所以完全靠着以前C语言的那点东西写了这一堆的代码,看起来就是混搭的不行不行的。。。。最主要的是。。。踩了不少坑 = =。由于我本人并不喜欢直接阅读那种协议的定义,所以写之前直接用了Wireshark来抓一个HTTP包做样本。(理工教务系统很抱歉这次又是你 = =)。
首先是直接访问 http://i.cqut.edu.cn,然后抓到下图所示的一个GET请求
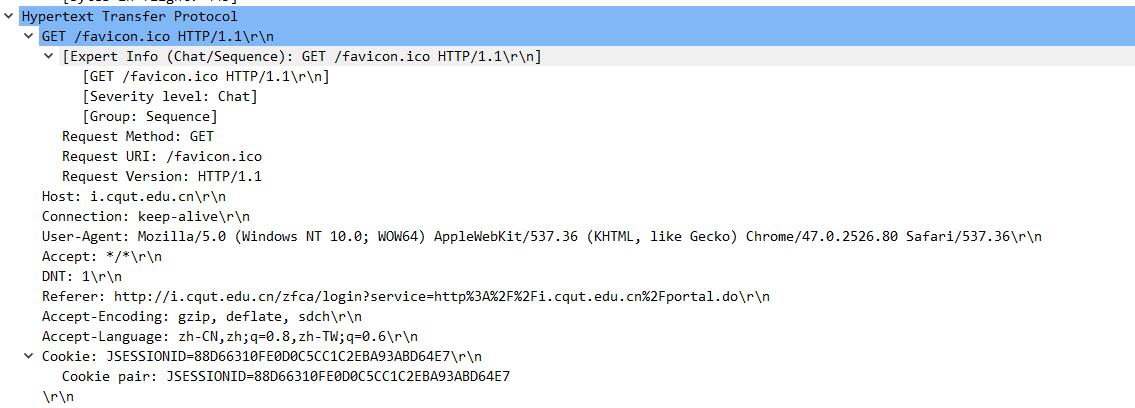
网络协议里面曾经讲过,HTTP协议包含几个部分,根据抓到的GET请求包可以看出来,一个完整的GET请求包含:请求方式(GET),请求目标(/favicon.ico),协议版本(HTTP/1.1),然后换行开始的数据为Header信息,每一行header都有一个rn结尾。header为Key-Value模式,用 “: ”(冒号空格)来连接。在Header信息结束后会额外加一个rn
然后随便输入一个用户名密码,抓一个POST请求
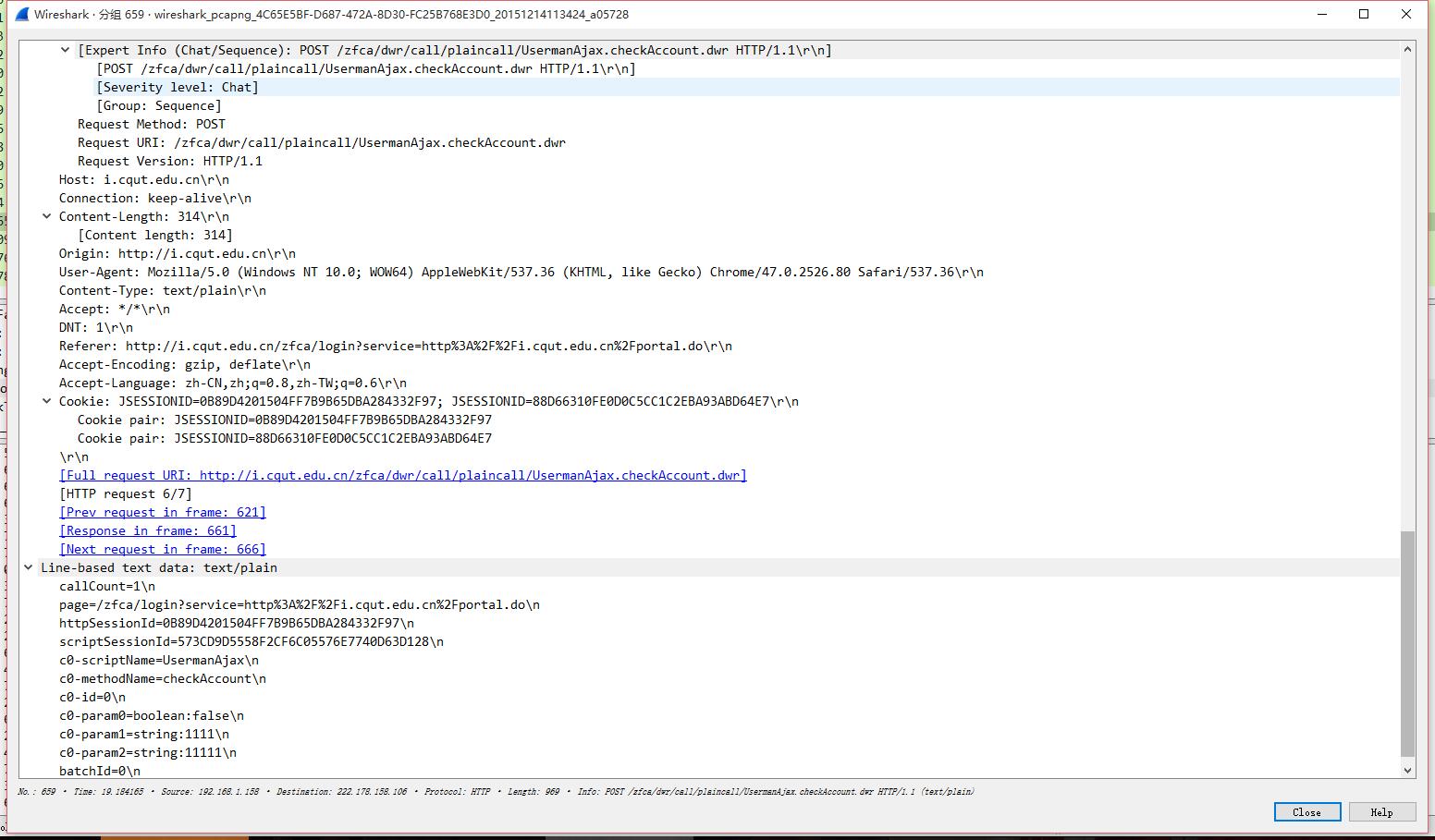
发现相比GET请求,POST请求多出的数据放在了header之后,这也就解释了为什么header之后为什么会有额外的rn,因为是用来区分header块和消息体块(数据块)的。
(图片可能需要点击放大)
所以综合上述数据包,一个大致的HTTP协议内容结构应该是:
请求方式(GET/POST等) 请求目标(/favicon.ico) 协议版本(HTTP/1.1)rn
<header>数据块,构成方式为<header名称>: <header数据值>rn
rn
消息体(数据)块
知道了这些,那么先构造一个协议构造函数。
/*
Send a http request to target host.
@Author CrazyChen@CQUT
@Date Dec 8 , 2015
@param addr Target Host Name , only ip or hostname allowed . e.g for http://192.168.1.1/myip.php the Host should be 192.168.1.1
@param port Host port for sending request.
@param isGet whether the request method is GET ( if value set to 1 ) or POST ( if value set to 0 )
@param target what's the file you want to request. e.g for http://192.168.1.1/myip.php the target should be /myip.php
@param headers The HTTP Headers Group , or NULL if no headers should be followed. Headers should be preprocessed like "Key: Value"
@param cookie The cookie you want to be sent,
@param data The Data You want to be sent , only if you set isGet=0 (POST Method)
@param replyData The Char Group For Storaging the reply data received from remote.
@return A HTTPRESPONSE Structure
**/
HTTPRESPONSE sendNet(const char * addr, int port, int isGet, const char* target, map<string, string>& headers, map<string, string>& cookie, const char * data){
HTTPRESPONSE response;//HTTP回复内容
if (!addr){
response.code = -1;
return response;
}
//以下代码用于在Windows下开启一个Socket
WSADATA wsaData;
if (WSAStartup(MAKEWORD(2, 2), &wsaData)){
response.code = -2;
return response;
}
SOCKET sock = socket(AF_INET, SOCK_STREAM, IPPROTO_TCP);
struct hostent *host = gethostbyname(addr);
SOCKADDR_IN SockAddr;
SockAddr.sin_port = htons(port >= 0 ? port : 80);
SockAddr.sin_family = AF_INET;
SockAddr.sin_addr.s_addr = *((unsigned long*)host->h_addr);
if (connect(sock, (SOCKADDR*)(&SockAddr), sizeof(SockAddr))){
response.code = -3;
return response;
}
//要发送的数据
string toSend;
//构造请求: GET/POST 《请求地址》 协议版本
toSend.append(isGet ? "GET " : "POST ").append((target == NULL || strlen(target) == 0) ? "/" : target).append(" HTTP/1.1rn");
string tmpHost = addr;
//将header放入其中
map<string, string> basicHeader = getBasicHeader(tmpHost, port);
if (!basicHeader.empty()){
map<string, string>::iterator headerIt = basicHeader.begin();
for (; headerIt != basicHeader.end(); ++headerIt){
toSend.append(headerIt->first).append(": ").append(headerIt->second).append("rn");
}
}
if (!headers.empty()){
map<string, string>::iterator headerIt = headers.begin();
for (; headerIt != headers.end(); ++headerIt){
toSend.append(headerIt->first).append(": ").append(headerIt->second).append("rn");
}
}
//对于POST请求,需要设置Content-Length标头以告诉远程提交的数据大小
//Set Content-Length
if (!isGet){
char len[10];
itoa(strlen(data), len, 10);
toSend.append("Content-Length: ").append(len).append("rn");
}
//处理Cookie字段至Header中
if (!cookie.empty()){
toSend.append("Cookie:");
map<string, string>::iterator cookieIt = cookie.begin();
for (; cookieIt != cookie.end(); ++cookieIt){
toSend.append(" ").append(cookieIt->first).append("=").append(cookieIt->second).append(";");
}
toSend.append("rn");
}
toSend.append("rn");
//如果是POST请求,则将消息块附加到后面
if (!isGet){
toSend.append(data);
}
send(sock, toSend.c_str(), toSend.length(), 0);
//循环接受
char buffer[BUFFER_LEN + 1] = { 0 };
int recvLen = 0;
while (1){
memset(buffer, 0, sizeof(char)* BUFFER_LEN);
recvLen = recv(sock, buffer, BUFFER_LEN, 0);
if (recvLen > 0){
response.recvStr.append(buffer);
continue;
}
break;
}
response.code = response.recvStr.length();
//使用自定义函数处理成一个HTTPRESPONSE
processResponse(&response);
return response;
}
最后拼出来的一个字符串应该形如:
POST / HTTP1.1rnHost: 192.168.1.1rnDNT: 1rnUser-Aagent: Sunflyer Testrnrn
然后,当你拿着这段代码测试一个请求的时候你会发现,如果你把其中getBasicHeader那部分代码去掉的话。无论如何你所请求到的内容都是400的状态码。这是因为header部分必须包含一个“Host”来指明你请求的是哪一个网站。
所以在此之前的getBasicHeader其实就是把请求的目标服务器和路径、端口给分开,拼出一个Host的header丢到里面去。一个典型的Host的header类似于: Host: 192.168.1.1:3389
而实际上公开给用户的get和post函数是不会这么写的,因为,你请求的是一个完整的URL,用户不能为了你的函数而去进行分割,所以分割操作需要你自己完成。
所以就有了这两个玩意儿
/*
Send a request using GET Method
@param url The request addr , without "http://"
@param cookie The cookie you would like to go
@param header The Header You want to be sent
@return a HTTPRESPONSE struct
**/
HTTPRESPONSE sendGet(const char * url, map<string, string> cookie, map<string, string> header){
string addr;
addr.append(url);
int path = addr.find("/");
string host = path > 0 ? addr.substr(0, path) : addr;
string target = path > 0 ? addr.substr(path) : "";
int port = 80;
if ((path = host.find(":")) != string::npos){
port = atoi(path + 1 >= host.length() ? "80" : host.substr(path + 1).c_str());
host = host.substr(0, path);
}
return sendNet(host.c_str(), port, 1, target.c_str(), header, cookie, NULL);
}
/*
Send a request using POST method
@param url The request addr , without "http://"
@param cookie The cookie you would like to go
@param header The Header You want to be sent
@param data The data you would like to post to server
@return a HTTPRESPONSE struct
*/
HTTPRESPONSE sendPost(const char * url, map<string, string> cookie, map<string, string> header, const char * data){
string addr;
addr.append(url);
int path = addr.find("/");
string host = path > 0 ? addr.substr(0, path) : host;
string target = path > 0 ? addr.substr(path) : "";
int port = 80;
if ((path = host.find(":")) != string::npos){
port = atoi(path + 1 >= host.length() ? "80" : host.substr(path + 1).c_str());
host = host.substr(0, path);
}
return sendNet(host.c_str(), port, 0, target.c_str(), header, cookie, data);
}
这样一来,实际使用的时候是要方便得多的,url里面不包含http://就行,而且也把cookie和header封装到map也更方便用户实际需求处理。
那么。。。。请求部分是完了,服务器返回的怎么处理呢?
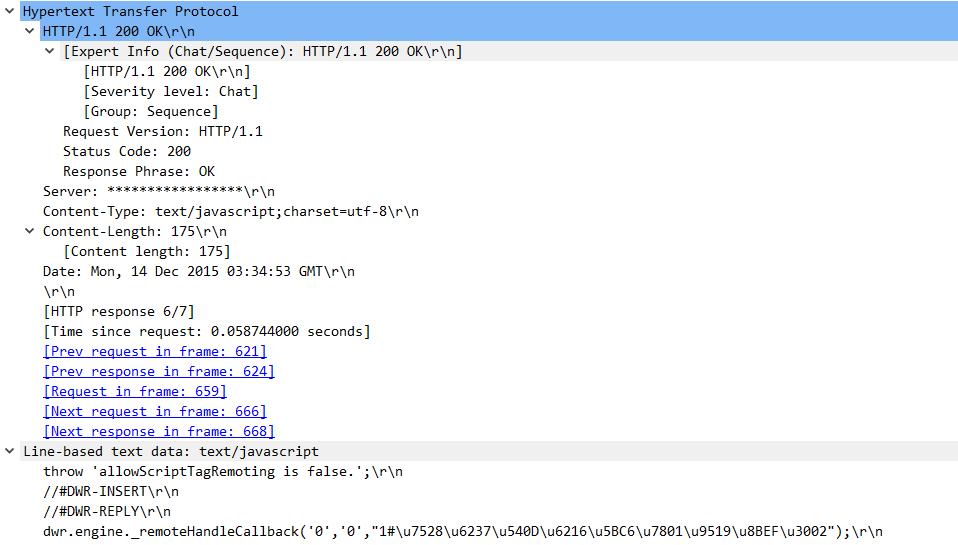
再看上图服务器发回的相应内容,可以看到,服务器返回的格式为:
首行: 协议版本 状态码 状态说明
<header>块
rn
响应数据
那简单,照着这个格式解析就好了。
void processResponse(HTTPRESPONSE * target){
if (target != NULL){
target->code = target->recvStr.length();
target->httpCode = 0;
if (target->code == 0){
target->code = -1;
return;
}
int path = target->recvStr.find("rnrn");
string header = target->recvStr.substr(0, path);
string content = target->recvStr.substr(path + 4);
vector<string> head;
split(header, "rn", head);
//process header , the first line should be SCHEME and STATUS CODE , use space to split
vector<string> temp;
split(head[0], " ", temp);
target->scheme = temp[0];
target->httpCode = atoi(temp[1].c_str());
target->httpCodeDescription = temp[2];
int tmpnum = -1;
string tmpstr;
for (int i = 1; i < head.size(); i++){
tmpnum = head[i].find(": ");
if (tmpnum >= 0){
tmpstr = head[i].substr(0, tmpnum);
if (!strcmp(tmpstr.c_str(), "Set-Cookie")){
tmpstr = head[i].substr(tmpnum + 2);
temp.clear();
split(tmpstr, "; ", temp);
int cook = -1;
for (tmpnum = 0; tmpnum < temp.size(); tmpnum++){
cook = temp[tmpnum].find("=");
if (cook > 0){
tmpstr = temp[tmpnum].substr(0, cook);
if (cook + 1 >= temp[tmpnum].length()){
target->cookie.insert(pair<string, string>(tmpstr, ""));
}
else{
target->cookie.insert(pair<string, string>(tmpstr, temp[tmpnum].substr(cook + 1)));
}
}
}
}
else{
target->header.insert(pair<string, string>(tmpstr, tmpnum + 2 >= head[i].length() ? "" : head[i].substr(tmpnum + 2)));
}
}
}
map<string, string>::iterator headerIt = target->header.find("Transfer-Encoding");
if (headerIt != target->header.end() && !headerIt->second.compare("chunked")){
target->recvStr = dealChunk(content);
}
else{
target->recvStr = content;
}
}
}
在上述代码中,首先是取得协议版本、状态码以及状态标识。然后对剩下内容以第一个rn分开(因为header和正文数据使用这个分开的),对第一部分进行header化处理,如果遇到Set-Cookie字段则表示是服务器发回的Cookie内容,放到一个专门的map中处理。
有小伙伴会问了,你最后的那个为什么还要判断是否有什么Chunked编码呢?
实际上这也是个坑 – – 当初把这部分做完的时候曾经天真的以为所有服务器都是按照这个样子的不会有别的花样了解析是没问题的,然而直到我把这段代码拿来测试Openwrt的登录。。。。返回的数据始终不是完整的,在显示一个“Transfer-Encoding: Chunked”以后就没有下文了。而且debug也显示没有更多数据。
WTF?这TM是什么鬼?
然后上WS抓包,结果发现一个很奇葩的情况。。。Wireshark显示长度为59,然而实际展开内容却有几十K。。。。
然后Wireshark显示了一个“Chunked Data”引起了我注意。这尼玛,什么意思,难道这玩意儿有啥内涵?
果断google之(度娘狗带),wiki上给出的说明是这是web服务器数据的一种传输方式,告诉客户端“我这次要返回的数据不是一次性发完的,而是分片发完的”,然后按照一定的格式发回给客户端。
根据这几次的操作发现,Chunked编码操作流程其实应该是:
- 服务器首先返回一个状态码和header,告诉浏览器“我要使用chunked编码了,你注意格式”
- 然后继续发送数据,格式类似于:
1A //后续数据长度
abcdefghijklmnopqrstuvwxyz//数据内容
6//再一次数据长度
123456//数据内容
0//结束
不要怀疑我这个格式是不是最后故意留这么多换行,而是实际就有的= =
如果你不对chunk编码处理的话,对于上述内容原本应该是“a……6”的,就成了“1Aabcdefg……….xyz61234560换行换行换行”这种了,显然会引起不必要的麻烦
那就写个处理过程咯
string dealChunk(string chunked){
string real;
if (chunked.length() > 0){
int len = 0, path = 0, pathCrLf = 0, flag = 0;
string tmp;
string proc = chunked;
while (proc.length() > 0){
len = path = flag = 0;
pathCrLf = proc.find("rn");
if (!pathCrLf){
pathCrLf = proc.find("rn", 2);
path += 2;
flag = 1;
}
if (pathCrLf > 0 && pathCrLf < 10){
tmp = proc.substr(path, pathCrLf);
sscanf(tmp.c_str(), "%x", &len);
path += tmp.length();
if (!flag){
path += 2;
}
// FA0 rn
tmp = proc.substr(path, len);
path += len;
real.append(tmp);
if (path >= proc.length())
break;
proc = proc.substr(path);
}
else{
real.append(proc);
break;
}
}
}
return real.substr(0, real.length() - 2);
}
这样一来,最后处理的数据也就能完完全全还原回来了。
至于其他的坑。。我都不想说。。。。c++ string的find返回的是uint搞得我拿 string.find(xxx) >0 一直为真。。。差点搞得我以为这段代码见了鬼了最后才知道实际上要用 find(xxx) != string::npos来比较是否真正找到了 = =
还有map不能直接map[“”]来取值,因为那个根本就不是这个用法 = = 正确的方式使用迭代器。。。
嗯。。。差不多就这样,又是代码比文字多系列。
学长能不能问下,你写教务系统爬虫的时候怎么处理那两个JSESSIONID的?
年代久远,已经忘了。。。但是没记错的话就是他给你的那个JSESSIONID你请求的时候带上给他就是了
请问HTTPRESPONSE 结构体在哪里?